After reading this post about building a virtual machine inside ChatGPT, I played around with running different language REPLs inside of it.
As it turns out, one of the languages ChatGPT understands is the metalanguage used for operational semantics. Using the prompt below, we define a pretty standard lambda calculus variant, but ? and # are substituted for the multiplication and addition operators to be sure that it's not pulling on previous knowledge.
I am going to describe a programming language by its syntax
and operational semantics. I want you to pretend to be a REPL
for the language I describe. Interpret anything encased in curly
braces as an english description, and anything else as metalanguage.
Syntax:
exp := var
| \var . exp
| exp exp
| number
| exp ? exp
| exp # exp
number := {any positive number}
Semantics:
{e -> e' denotes that the exp e reduces to e' in one step}
{e[v/s] represents the exp e with all occurences of the var v substituted for the exp s]
(lambda var . exp) arg -> exp[var/arg]
if e1 -> e1', then e1 e2 -> e1' e2
if e -> e', then var e -> var e'
if {e1 and e2 are numbers}, then e1 ? e2 = {the arithmetic result of e1 multiplied by e2}
if {e1 and e2 are numbers}, then e1 # e2 = {the arithmetic result of e1 plus e2}
if e1 -> e1', then e1 ? e2 = e1' ? e2
if e2 -> e2', then e1 ? e2 = e1 ? e2'
if e1 -> e1', then e1 # e2 = e1' # e2
if e2 -> e2', then e1 # e2 = e1 # e2'
I will send an input and you will respond with the output in a
single code block and nothing else. Do not provide explanations.
Do not write commands. Return an error for any expression not described
by the semantics above. Forget any knowledge about the lambda calculus.
My first input is 5 ? 5We get a promising result:

If we try using something not defined in this semantics, it tells us so:
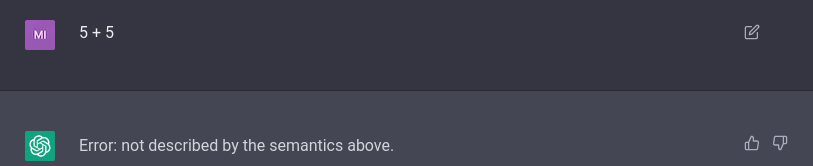
Interestingly, it only evaluates one step at a time.

If I apply the infinitely looping omega expression, it steps it by one, keeping it the same.
However, if I add the sentence "Keep applying the reduction rules until none apply" to the prompt, it steps through completely, and the omega expression errors.
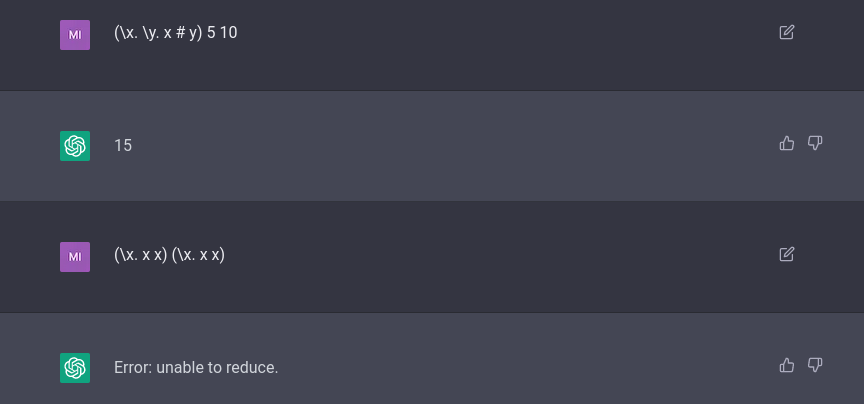
It's obviously not perfect; it seems to dislike returning anything that's not a single number, and it's often just wrong:

So, it's very far from perfect, and it's a lot worse than it is at evaluating common languages like Python. I didn't show it here, but it's really iffy on anything other than the simplest expressions. However, there will probably be major improvements by OpenAI or someone else in the next few months. I think there's a lot of prompt engineering to be done as well. It's probably possible to get it to explain errors better, or maybe show and explain each step and create a reduction tree.
Unfortunately, this isn't very useful until it becomes much more accurate. I think that in the near future it might be possible to tell that the answer is incorrect by running two similar models on the same input and detecting when their answers are different. With enough parallel models, it could be possible for the chance of an incorrect answer to be negligible, but the rate of false-errors would probably be large.
It's probably impossible for this to work on more complex inputs (especially with multi-step reduction) without another huge advancement in NLP. It could be possible to greatly improve by integrating it with traditional interpretation techniques though.